Volgende: Web services Omhoog: Solution concepts Vorige: Introduction Inhoudsopgave
BC uses many technical terms, estimates go up to 300k [34]. Most BC terms describe components, materials, connections, equipment and such. Other terms identify verbs like `painting', `driving' and again others describe properties, units and such. Formally defining so many terms is not a simple task. Still that is what is needed if computers will ever be able to help to enhance the industry's capacity to communicate and co-operate.
As a first point, note should be taken of the comments in Chapter 3 on standards and standardisation processes. The analysis showed a low success rate for committee-developed standards. This does not, however, exclude the eventual standardisation of a de facto market-developed set of Semantics by a standardisation institute, should the need arise. The analysis shows that development of a de jure standard in a standardisation process does neither guarantee marketplace adoption nor results as such. For this research, a desired end result is a marketplace-developed de facto standard [92].
As analysed in chapter 3 and chapter 4, BC Semantics is a basic requirement for improved communication. For this basic requirement, it is necessary that adoption is not hindered by costs. The lower the cost, the higher, normally, adoption. With low costs, the cost of actually collecting the fees might easily be higher than the amount collected. Likewise, a fee collection process means a controlling organisation, which leans towards the committee-based standard development that was discussed above. The BC semantic basis, therefore, would ideally be free (gratis). (The economic basis will be discussed in more detail in section 6.5).
In Chapter 4, the success factors for Internet-based developments have been analysed. BC Semantics need to be generally available and simple to allow the knowledge chains to unambiguously express their knowledge. The BC Semantics end-result should therefore be available in a simple, generally understood form that can be used without needing applications that are not generally available or affordable. Access should be unrestrained, both technically and juridically.
In practical terms, the desired end-result should be BC Semantics that are available on-line, for free, in a generic computer-readable format.
As of the size of the problem domain, it is imperative that a healthy `ecosystem' develops, in which every interested party can contribute and cooperate. The end-result should therefore allow for a way to do distributed development and maintenance of BC Semantics, without having a centralised organisation serving as a potential choke-point. There is nothing wrong with one organisation having a more dominant role, the Semantics should however not be dependent on that organisation: no monopolisation.
From the analysis, it becomes clear that it is probably a dream to make one single set of BC Semantics that will be used all the time, everywhere. This means that the end-result should be flexible: the definitions should be referenceable, it should be possible to use the definitions as a basis for communication by referencing them. This way one can either use the Semantics directly, or one can use them to communicate between two differing Semantics. The end-result should not force itself to be built directly into everything that uses it; it should be referenced only.
The next section discusses a development-friendly clustering of terms.
While focusing on the object definitions themselves, the first problem is to find a solution for ordering so many BC terms used by the stakeholders active in BC: civil engineering, house construction, infrastructure, architecture, waterworks and other sectors.
The previous section concluded that the end-result should allow for distributed development and maintenance of the BC Semantics. Distributed development calls for a subdivision of the problem to split up the work. A second reason is to provide a measure of local organisation to coordinate the work.
Which demands should be satisfied by a clustering of terms? The overarching goal is to achieve a complete set of terms, capable of supporting BC. Smoothing and supporting the actual development of that set of terms should therefore be the top demand. A simple and clear process allows the greatest participation. A clustering should be clear and simple for the people adding and maintaining the terms.
A first subdivision of the problem area is to restrict the development to a national scale instead of an international scale, at least initially. Not having to deal with translation issues and local practices makes the process much simpler for most participants.
A second possibility is to cluster by work discipline or sector: bridges, installations, roofs. The resulting clusters are quite big, but the majority of the terms will be familiar to the participants. The clusters are even bigger if you cluster by ground/waterworks, buildings, equipment, etc.
A third possibility is to cluster by supplier industry. The suitability depends on the level of participation of suppliers, but in any case the resulting clusters will tend to be smaller than sector clusters. This might make it more manageable on the one hand, but too small for meaningful interrelations on the other hand.
For these sets of term definitions, the word Ontology is often used. An Ontology8.1 is a conceptualisation (meaning definitions of terms) of a specific domain (a certain cluster), made from the viewpoint of that domain [27]. The term itself acknowledges the fact that an Ontology is restricted to a certain domain and it is made from the specific viewpoint of that domain.
The word used from now on to indicate BC Semantics, so the definitions of terms, is `Building-Construction Ontology'.
The technical implementation of subdividing the problem area into several Ontologies will be done using the NG Internet OWL standard (analysed in chapter 4). Every cluster will be given its own OWL file. For unique identification of the terms in an OWL Ontology, OWL uses the NG Internet mechanism of giving every term its own URL. Every OWL Ontology should get its own `base' URL. This way, no Ontology can overlap another, at least not on a technical level. An English door Ontology might start all its term identifications with http://en.bcoweb.org/doors/ and a German bridge-building Ontology with http://de.bcoweb.org/bruecke/.
The next section shows how these cluster-based Ontologies can be related to each other in a network.
The clustering explained above greatly helps to make the development process simpler for the participants. BC as a whole, though, should not be limited or hindered by the development-friendly clustering. What is needed is a way to be able to see all the different Ontologies as one whole or as one connected network, so that BC as a whole can be supported.
A second reason to desire a connected network is the duplicated effort the participants need to expend if every cluster has to develop their own solution for common items. For example, foundations occur under houses, but also under stadiums and bridges8.2. Every cluster would need to enter the same information; information that should preferably be shared. Figure 6.1 shows a simple schematic example.
Instead of one single unified Ontology, multiple separate Ontologies are proposed. This allows an individual company or industry sector to create and maintain their own Semantics. It also obviates the need for a central controlling entity. To allow generic usage and to allow improvements (which might be needed in such a less-controlled, decentralised approach), a specific open source license (FDL [89] or CC [90]) on the content is part of the concept--as was recommended as a very interesting new effort at creating a useful basis for web-based communication in Chapter 4.
The distributed approach necessitates a linking-together of the Ontologies on their contact points: a network of partially cooperating Ontologies is envisioned.
The OWL Ontology format is build on RDF, the linking mechanism of the NG Internet. This allows you to link from one item in an Ontology (identified by a URL) to another item in another Ontology (also identified by a URL). This makes it possible to say that one of the `parts' of a `bridge' (in a Civil Engineering Ontology) is a `foundation' (which is found in a Housing Ontology).
|
|
In this way, a network of Ontologies can provide BC with the Semantics needed. The drawback of having the Semantics spread out over multiple Ontologies is negated. In keeping with the Internet, the Ontology network will be called a web: the bcoWeb.
Object definitions can be structured in many ways, see the analysis in chapter 3 and chapter 4.
As supporting a more dynamic BC is a base requirement, the interaction between Demand and Supply is important. The GARM8.3FU/TS model supports the Demand/Supply distinction on the Ontology level and is proposed as a basis, see section 3.3.4. The FU/TS distinction provides a natural contact point to link together Ontologies in a network.
Following ideas expressed by Van Nederveen [93] and Gieling [54] terms are divided in `functional units' (called `functions' by Van Nederveen) and `technical solutions' (called `function performers' by Van Nederveen). Demanding parties express their demands in functional terms, and supplying parties express their supply or offering in technical terms. For each functional unit a number of technical solutions (function performers) can be provided.
A specific goal is to help close the gap between Demand and Supply. Therefore the starting point is to take the selection of a particular technical solution for a given set of functions into the core of the meta-model. Each object, large or small, can be viewed from a functional perspective (what) and a technical perspective (how). The functional characteristics of an object are collected in what is here called a FU. The technical characteristics are collected in what is here called a TS. Selecting the appropriate TS among a number of alternative TSs is represented in figure 6.2.
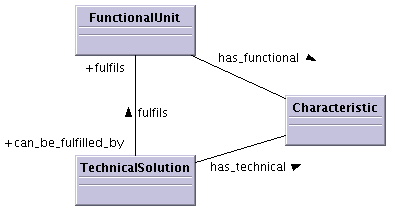 |
Once the basic FUs and TSs have been made available in the Ontology web, new TSs can be added by the Supply side and subsequently be found and evaluated by the Demand side. Also note that the UML model says that a TS can satisfy multiple FUs at the same time, i.e. a particular type of `outer wall' can fulfill both separation requirements (temperature, noise, safety) and structural safety requirements. Note also that a particular FU can be satisfied by the technical characteristics of more than one TS.
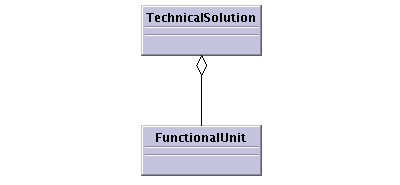
The second key construct is the fact that each TS is made up of a set of lower objects that again can be viewed from both a functional and technical perspective. Figure 6.3 formalises this fact.
Besides the simple FU and TS, the concept suggests one other object type: the FU-set8.4. The FU-set is a collection of objects that collects a set of FUs. The reason for its introduction is that it can be used to express that objects like `water crossing' are more a grouping of FUs than that they are a FU themselves. The FUs contained in the set `water crossing' can then be `tunnel', `bridge', `ferry', and such. Modelled like this the FU `bridge' can then be matched to various types of bridges, like `suspension bridge'.
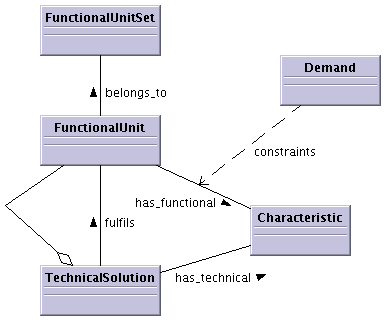
Figure 6.4 shows the complete meta model. Note that there is also an object called Demand which constrains the functional characteristics to become a demand (height < 30.0 cm).
 |
At this point, the model is really a simple version of the original GARM model: a lot of things are missing, like restrictions and properties. The simpleness of the model has attractive sides: it is relatively easy to explain and easy to work with. As an example, one graduate student added some 1000 concepts including relations in three months time [94].
Properties normally should be integrated into the model, but the use of OWL allows the possibility of keeping the properties external. In the external case, the FU/TS data is combined with one or more OWL files defining the properties before being used by data. Using OWL's possibility to combine several classes into one new class, the various source classes can be kept separate without cross-pollution.
An advantage of keeping the properties out of the FU/TS data is that the model stays simple and focused. A disadvantage is that properties are very important: keeping them external might make the FU/TS data less practice-oriented, as adding properties to a concept makes you think harder about that concept's reality. External properties allow the use of various abstraction levels. Not everybody is interested in the same properties or the same amount of properties. External properties invite you explicitly to take this into account, which might lead to results that are more practice-oriented.
Including properties directly in the FU/TS data makes the model less simple, but the importance of properties warrants that. A problem is the variance in abstraction levels at which users of the system think: for ordering a window, five properties might be enough, but, for making a window in a CAM setting, 85 properties are needed [95]. It seems clear that to keep the system workable, at least some properties have to be kept external. This is supported by OWL, so it presents no technical problems.
Apart from properties, restrictions are also part of the original GARM. Functional units are generic building blocks that can be re-used in other parts of the model, for instance a FU `foundation' that is used by bridges, houses, stadiums. These FU building blocks are sometimes too generic: not all technical solutions for that FU are applicable for a certain object, so the non-applicable TSs have to be filtered out.
As an example, a `bungalow' in the Netherlands indicates a house with just a floor on ground level and with a flat roof. For the technical solution `bungalow', it would be handy to re-use FU `foundation', FU `roof' and so on. But FU `roof' includes TSs that are not allowed for `bungalow'. The simplest way to solve this is to restrict the list of TSs for a certain FU when some object higher up in the hierarchy occurs.
This restriction mechanism does not directly cover restrictions on properties or more complex interactions, but it provides a basis for further elaboration. It should be implemented in such a way, using OWL's extension mechanisms, that allows others to add more restrictions. The restrictions can be a good way of adding knowledge to the system.
A final word about instances of a FU/TS model. The tree structure invites you to use a tree structure on the data side (=instance), too. For many uses this might be a good solution, as bcoWeb aims to keep the FUs and TSs close to practice, something reinforced by the model.
When looking at the so-called objecttree solution, a difference is that an objecttree consists of per-project individual objects or sets of objects [93]. A bcoWeb-based instantiation tree uses general definitions instead of locally (un)defined objects. A combination of the two might be attractive: instantiated bcoWeb objects when possible, interspersed with locally defined objects. The locally defined objects, when useful, can be considered for addition8.5 to bcoWeb, either as a separate Ontology or added to existing ones.
Other initiatives to create BC Ontologies exist (see chapter 3 and 4) and for instance Classification systems have a fixed place. The acknowledgement that cooperation with other initiatives is needed is inherent, in a way, to a concept that itself consists of a Web of cooperating Ontologies.
Interaction can take place in three ways: directly on the Ontology level, on the data level and `via the data'. On the Ontology level means direct mapping from the Ontology to a Classification system or a PDT standard. On the data level, the second way, the data is linked to the Ontology and to another system. In this case, the Ontology needs to know nothing, but it means double work on the data level. A third way is to do the linking on the data level, but to try to extract an Ontology-level mapping out of the data level links later on. This can be done automatically, but is highly dependent on the accessibility of the data and and the availability of a sufficient data quantity.
Classification systems can be very important for Ontologies as they summarise and organise existing knowledge [96], connecting Ontologies to existing experience and perhaps making them more instantly familiar.
When dealing with Classification systems, the easiest approach is to directly classify the BC Ontology classes in the Classification's classes. All BC Ontology `door' objects should end up in STABU's `doors and windows' category, for instance. The nature of BC Ontologies and of Classification systems is an advantage here. BC Ontologies will have relatively many object classes, as it should be detailed enough for meaningful computer-based information exchange. Classification systems, on the other hand, have relatively few classes, as it would otherwise become unclear and unmanageable for the human actors that it is intended for. Classifying a detailed BC Ontology in the appropriate Classification classes will leave just a few border cases that are difficult to classify.
With regard to PDT efforts like IFC or 12006-3, Ontology-level cooperation is more difficult because the level of detail does not differ that much. This similarity in detail makes it unlikely that most classes fit exactly, because of the difference in viewpoints of the Ontologies. This makes for a lot of corner cases: partly overlapping classes.
The actual BC objects described are the same, so on the data level it is clearer which Ontology classes (object definitions) should be used. Though it is more work, you could reference more than one Ontology when needed. This is a data-level mapping. In certain cases, a data object could be seen as an instance of two Ontology classes.
The BC Ontologies proposed are each a domain-specific cluster of terms. Within individual clusters, a more Ontology-level mapping could be made if another Ontology is also used a lot in that domain. Another option is to try to recast another Ontology that is popular in a certain domain into a more demand/supply viewpoint by providing a thin wrapper.
The BC Ontology concept proposed provides an additional angle for cooperation. As the proposed concept is based on a supply/demand viewpoint, there are two possibilities for cooperation: on the functional side and on the technical side. If another Ontology is more function-oriented, cooperation just on the demand side is a good opportunity, for instance.
Mappings made on the data level can be automatically turned into partly Ontology-level mappings if enough data level mappings are available. The next section, on web services, shows that data can be automatically mined for useful information. One of the possible applications is the generation of a first-effort mapping, which can later be enhanced.
A network of national domain-specific object definitions should be created. By making them on-line available, they are referenceable and can be used to improve the communication between all stakeholders, including the general public. The concept is called bcoWeb.
A clustering in national domain-specific Ontologies allows for a distributed development, making the concept developer-friendly. The drawback of separate Ontologies is negated by placing them in a NG Internet-supported network.
The Ontology structure is based upon a Supply/Demand distinction by using the FU/TS principle from the GARM, which has not been used on such a level. This principle has the advantage that it specifically targets the interaction points between objects and thus communication itself. It provides BC with a growth opportunity towards further integration and knowledge sharing.
Reinout van Rees 2006-12-13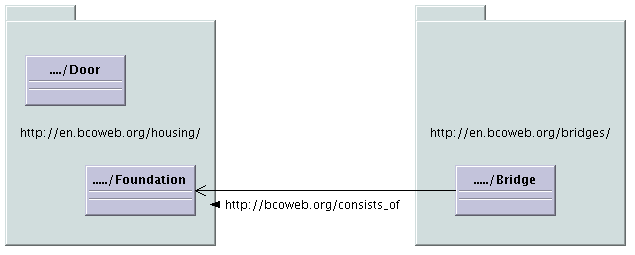
{kind=link}
{kind=link}
{kind=link}
{kind=link}